Abbiamo visto nel pezzo precedente cosa sono i selettori XPath e perchè sono importanti per trovare i dati che vogliamo all’interno di un documento HTML.
Ma questo tipo di selettori hanno una sintassi particolare che all’inizio può essere difficile da comprendere, quindi: come possiamo fare per conoscere i selettori giusti da utilizzare?
Se andiamo a vedere la struttura di una pagine, pur semplice che sia, risulta davvero ostico andare a riconoscere la parte di codice HTML che rappresenta il nodo che contiene i dati che ci interessano.
Per fortuna ogni browser moderno è dotato di alcuni strumenti per sviluppatori, accessibile premendo il tasto F12 oppure andando a selezionare direttamente il nodo che ci interezza e cliccando con il pulsante destro del mouse andare a scegliere l’opzione ‘Esamina elemento’ o ‘Inspect’ a seconda del browser.
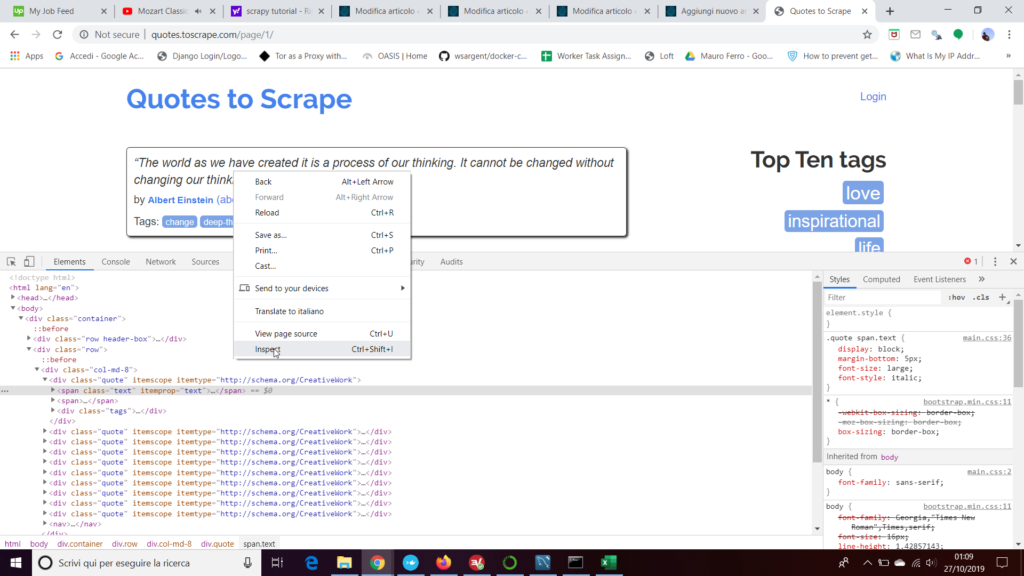
Usando questa ultima opzione ci verrà mostrata nella console per sviluppatori la parte di codice che HTML rappresenta l’elemento sul quale abbiamo cliccato.
A questo punto per ottenere il selettore XPath è sufficiente andare a cliccare con il tasto destro del mouse sulla porzione di codice HTML che ci interessa selezionare il comando ‘Copia…’ e poi andare a selezionare l’opzione che ci interessa ovvero ‘Copia XPath’. Avremo cosi nella memoria del blocco appunti il selettore XPath univoco per quell’elemento.
Se vuoi una dimostrazione pratica puoi guardare il breve video qui sotto riportato, dura meno di un minuto.