
Negli ultimi anni si è sentito parlare sempre più spesso di Machine Learning e di Intelligenza Artificiale diventando uno dei temi più attuali. In realtà una prima definizione del Machine Learning è stata fatta nel 1950 da Arthur Samuel, uno dei pionieri dell’intelligenza artificiale, che definiva questa branca dell’informatica in questo modo:
Il machine learning è il “campo di studio che dà ai computer l’abilità di apprendere (a realizzare un compito) senza essere esplicitamente programmati a farlo”.
Arthur Samuel
Nella programmazione classica l’elemento alla base di ogni elaborazione o software è l’algoritmo: un procedimento che viene utilizzato per poter risolvere un determinato problema. Si parte da una serie di input e procedendo in modo sistematico attraverso una serie di passaggi con possibili scelte predeterminate si arriva ad una conclusione che produce un output. Per fare un esempio con la vita reale: la semplice ricetta di una torta è un algoritmo che ci permette di ottenere una calda crostata di mele partendo da alcuni input e processandoli attraverso una serie di elaborazioni.
Alcuni procedimenti possono essere risolti ed elaborati attraverso la creazione di specifici algoritmi che prevedano tutte le possibili scelte e soluzioni, mentre altri problemi sono di una natura tale che la creazione di un algoritmo non è possibile o prevederebbe una così vasta serie di variabili e passaggi da renderne la creazione impossibile.
Riconoscere il contenuto di una fotografia, insegnare un’auto a guidare da sola, creare un metodo efficacie di raccomandazione prodotti o un sistema di fraud detection sono tutti compiti che potrebbero essere risolti sempre con un algoritmo: ma le dimensioni di istruzioni ed il numero delle variabili da creare sarebbe talmente vasto da renderne impossibile la realizzazione.
Ad esempio non è umanamente possibile creare un programma che riconosca se in una fotografia è presente la figura di un cane, di un gatto o di un volto umano attraverso la realizzazione di un algoritmo… qui entra in gioco il Machine Learning!
Il Machine Learning è quella branca dell’informatica che permette ai computer di addestrarsi in modo autonomo: vengono forniti alla macchina una vasta quantità di input ed una serie di ouput lasciando che sia la macchina stessa a determinare l’algoritmo ottimale per risolvere il problema. In sostanza il Machine Learning serve per insegnare alle macchine a realizzare in maniera autonoma degli algoritmi per la soluzione di un problema.
Questo insegnamento nel machine learning supervisionato avviene attraverso due passaggi:
- L’addestramento: dove vengono forniti una serie numerosa di esempi di input ed output in base alla quale la macchina deve poter generare un proprio algoritmo, che nel mondo del machine learning viene chiamato modello.
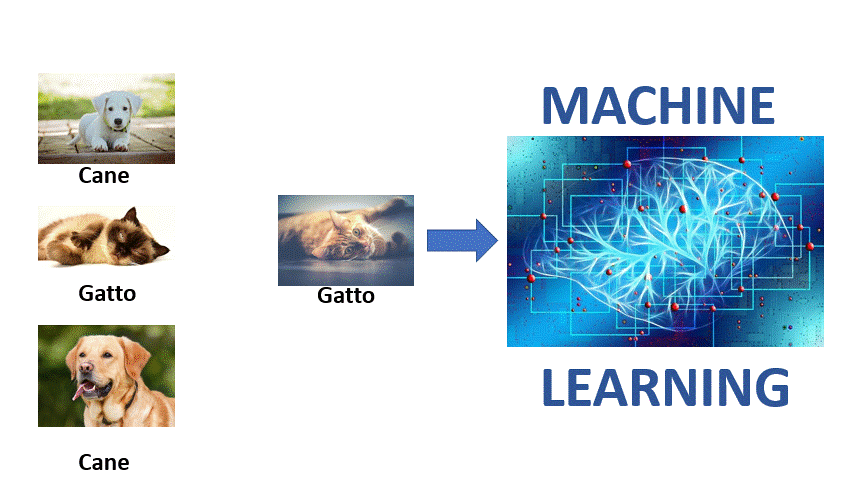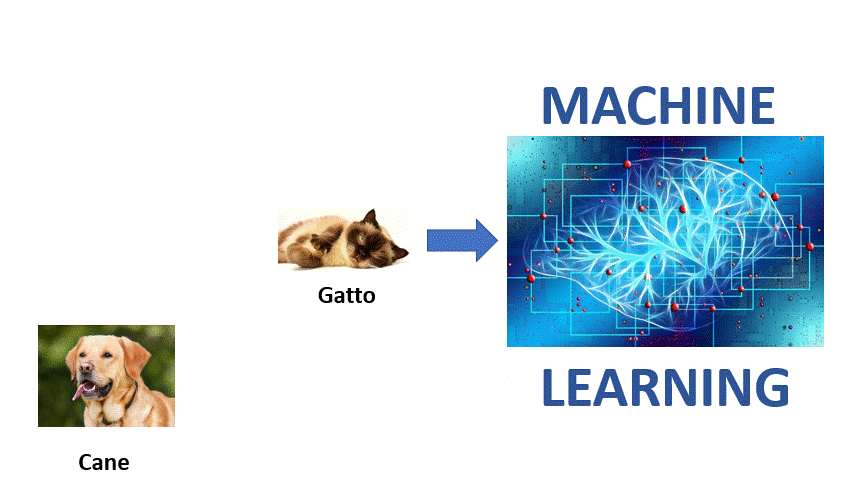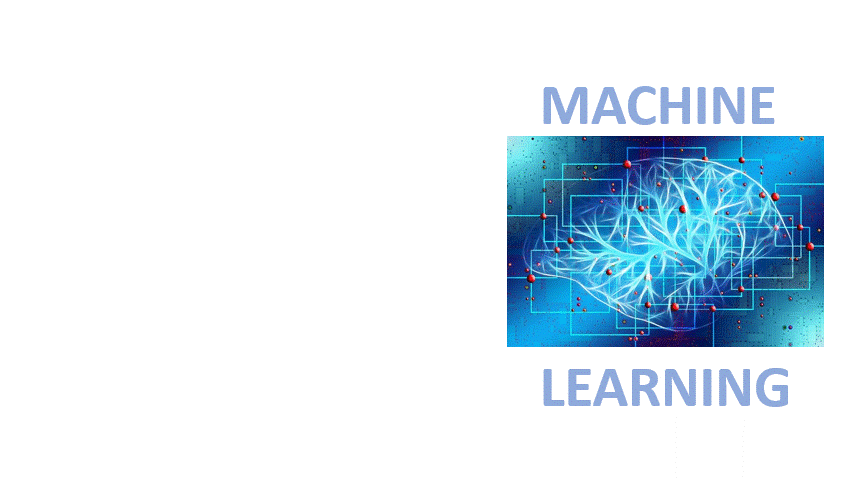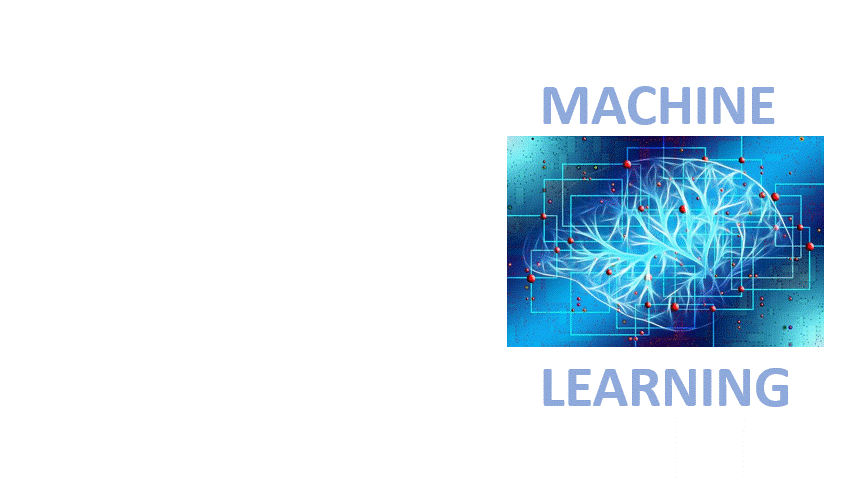
- La Predizione: una volta finito l’addestramento con una mole di dati ed esempio sufficientemente grande è possibile effettuale la predizione degli output semplicemente fornendo degli input (ad esempio mostrando una foto di un cane o un gatto il computer sarà in grado di determinare a quale categoria appartiene il soggetto della foto).

Ovviamente esisterà un margine di errore, quello di cui si occupa un Data Scientist nel machine learning è la realizzazione di modelli con margini di errori sempre più ridotti. Nel machine learning classico le tipologie di problemi che bene si adattano ad essere risolti sono quelle che presentano una relazione lineare e che possono essere predetti attraverso l’individuazione di una certa correlazione tra input ed output.
Per modelli più complessi non lineari ci si deve affidare ad altra tecnologia nata verso la fine degli anni ’80: quella delle reti neurali, dove aumentando il livello di attrazione del problema sarà possibile per la macchina andare ad individuare una certa correlazione.
Perchè il machine learning si diffonde solo oggi?
Può sorgere spontanea la domanda: se viene concepito nel 1950 e negli anni ’80 viene migliorato ampliandone il campo di applicazione per che il machine learning si diffonde solo ora?
Principalmente per due motivazioni:
- la prima è la presenza al giorno d’oggi di una quantità di dati enorme (i Big Data) che si sono creati inseguito alla diffusione di Internet;
- la seconda è la potenza di calcolo raggiunta dalla macchine moderne che una volta era impensabile. La potenza che teniamo nel palmo di una mano all’interno del nostro smartphone e decisamente superiore dei computer che hanno permesso lo sbarco sulla luna.
Se siete curiosi e volete maggiori informazioni sull’argomento suggeriamo di procedere con calma e leggere l’articolo sulla regressione lineare nel machine learning.